The Mean-Shift clustering algorithm is a non-parametric clustering algorithm that works by iteratively shifting the mean of a data point towards the densest area of the data. The densest area of the data is determined by the kernel function, which is a function that assigns weights to the data points based on their distance from the mean. The kernel function used in Mean-Shift clustering is usually a Gaussian function.
The steps involved in the Mean-Shift clustering algorithm are as follows −
- Initialize the mean of each data point to its own value.
- For each data point, compute the mean shift vector, which is the vector that points towards the densest area of the data.
- Update the mean of each data point by shifting it towards the densest area of the data.
- Repeat steps 2 and 3 until convergence is reached.
The Mean-Shift clustering algorithm is a density-based clustering algorithm, which means that it identifies clusters based on the density of the data points rather than the distance between them. In other words, the algorithm identifies clusters based on the areas where the density of the data points is highest.
Implementation of Mean-Shift Clustering in Python
The Mean-Shift clustering algorithm can be implemented in Python programming language using the scikit-learn library. The scikit-learn library is a popular machine learning library in Python that provides various tools for data analysis and machine learning. The following steps are involved in implementing the Mean-Shift clustering algorithm in Python using the scikit-learn library −
Step 1 − Import the necessary libraries
The numpy library is used for scientific computing in Python, while the matplotlib library is used for data visualization. The sklearn.cluster library contains the MeanShift class, which is used for implementing the Mean-Shift clustering algorithm in Python.
The estimate_bandwidth function is used to estimate the bandwidth of the kernel function, which is an important parameter in the Mean-Shift clustering algorithm.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import MeanShift, estimate_bandwidth
Step 2 − Generate the data
In this step, we generate a random dataset with 500 data points and 2 features. We use the numpy.random.randn function to generate the data.
# Generate the data
X = np.random.randn(500,2)Step 3 − Estimate the bandwidth of the kernel function
In this step, we estimate the bandwidth of the kernel function using the estimate_bandwidth function. The bandwidth is an important parameter in the Mean-Shift clustering algorithm, which determines the width of the kernel function.
# Estimate the bandwidth
bandwidth = estimate_bandwidth(X, quantile=0.1, n_samples=100)Step 4 − Initialize the Mean-Shift clustering algorithm
In this step, we initialize the Mean-Shift clustering algorithm using the MeanShift class. We pass the bandwidth parameter to the class to set the width of the kernel function.
# Initialize the Mean-Shift algorithm
ms = MeanShift(bandwidth=bandwidth, bin_seeding=True)Step 5 − Train the model
In this step, we train the Mean-Shift clustering algorithm on the dataset using the fit method of the MeanShift class.
# Train the model
ms.fit(X)Step 6 − Visualize the results
# Visualize the results
labels = ms.labels_
cluster_centers = ms.cluster_centers_
n_clusters_ =len(np.unique(labels))print("Number of estimated clusters:", n_clusters_)# Plot the data points and the centroids
plt.figure(figsize=(7.5,3.5))
plt.scatter(X[:,0], X[:,1], c=labels, cmap='viridis')
plt.scatter(cluster_centers[:,0], cluster_centers[:,1], marker='*', s=300, c='r')
plt.show()In this step, we visualize the results of the Mean-Shift clustering algorithm. We extract the cluster labels and the cluster centers from the trained model. We then print the number of estimated clusters. Finally, we plot the data points and the centroids using the matplotlib library.
Example
Here is the complete implementation example of Mean-Shift Clustering Algorithm in python −
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import MeanShift, estimate_bandwidth
# Generate the data
X = np.random.randn(500,2)# Estimate the bandwidth
bandwidth = estimate_bandwidth(X, quantile=0.1, n_samples=100)# Initialize the Mean-Shift algorithm
ms = MeanShift(bandwidth=bandwidth, bin_seeding=True)# Train the model
ms.fit(X)# Visualize the results
labels = ms.labels_
cluster_centers = ms.cluster_centers_
n_clusters_ =len(np.unique(labels))print("Number of estimated clusters:", n_clusters_)# Plot the data points and the centroids
plt.figure(figsize=(7.5,3.5))
plt.scatter(X[:,0], X[:,1], c=labels, cmap='summer')
plt.scatter(cluster_centers[:,0], cluster_centers[:,1], marker='*',
s=200, c='r')
plt.show()Output
When you execute the program, it will produce the following plot as the output −
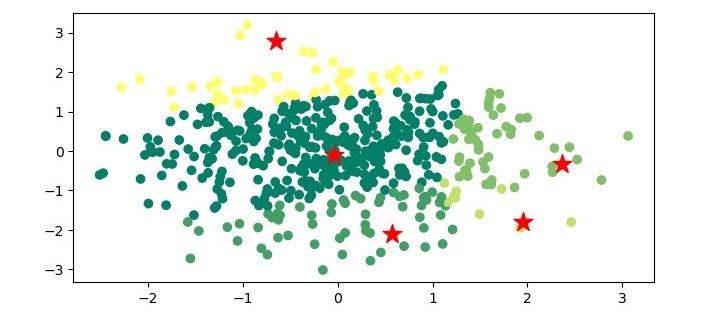

Applications of Mean-Shift Clustering
The Mean-Shift clustering algorithm has several applications in various fields. Some of the applications of Mean-Shift clustering are as follows −
- Computer vision − Mean-Shift clustering is widely used in computer vision for object tracking, image segmentation, and feature extraction.
- Image processing − Mean-Shift clustering is used for image segmentation, which is the process of dividing an image into multiple segments based on the similarity of the pixels.
- Anomaly detection − Mean-Shift clustering can be used for detecting anomalies in data by identifying the areas with low density.
- Customer segmentation − Mean-Shift clustering can be used for customer segmentation in marketing by identifying groups of customers with similar behavior and preferences.
- Social network analysis − Mean-Shift clustering can be used for clustering users in social networks based on their interests and interactions.
Leave a Reply