Backward Elimination is a feature selection technique used in machine learning to select the most significant features for a predictive model. In this technique, we start by considering all the features initially, and then we iteratively remove the least significant features until we get the best subset of features that gives the best performance.
Implementation in Python
To implement Backward Elimination in Python, you can follow these steps −
Import the necessary libraries: pandas, numpy, and statsmodels.api.
import pandas as pd
import numpy as np
import statsmodels.api as sm
Load your dataset into a Pandas DataFrame. We will be using Pima-Indians-Diabetes dataset
diabetes = pd.read_csv(r'C:\Users\Leekha\Desktop\diabetes.csv')Define the predictor variables (X) and the target variable (y).
X = dataset.iloc[:,:-1].values
y = dataset.iloc[:,-1].values
Add a column of ones to the predictor variables to represent the intercept.
X = np.append(arr = np.ones((len(X),1)).astype(int), values = X, axis =1)Use the Ordinary Least Squares (OLS) method from the statsmodels library to fit the multiple linear regression model with all the predictor variables.
X_opt = X[:,[0,1,2,3,4,5]]
regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit()Check the p-values of each predictor variable and remove the one with the highest p-value (i.e., the least significant).
regressor_OLS.summary()Repeat steps 5 and 6 until all the remaining predictor variables have a p-value below the significance level (e.g., 0.05).
X_opt = X[:,[0,1,3,4,5]]
regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit()
regressor_OLS.summary()
X_opt = X[:,[0,3,4,5]]
regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit()
regressor_OLS.summary()
X_opt = X[:,[0,3,5]]
regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit()
regressor_OLS.summary()
X_opt = X[:,[0,3]]
regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit()
regressor_OLS.summary()The final subset of predictor variables with p-values below the significance level is the optimal set of features for the model.
Example
Here is the complete implementation of Backward Elimination in Python −
# Importing the necessary librariesimport pandas as pd
import numpy as np
import statsmodels.api as sm
# Load the diabetes dataset
diabetes = pd.read_csv(r'C:\Users\Leekha\Desktop\diabetes.csv')# Define the predictor variables (X) and the target variable (y)
X = diabetes.iloc[:,:-1].values
y = diabetes.iloc[:,-1].values
# Add a column of ones to the predictor variables to represent the intercept
X = np.append(arr = np.ones((len(X),1)).astype(int), values = X, axis =1)# Fit the multiple linear regression model with all the predictor variables
X_opt = X[:,[0,1,2,3,4,5,6,7,8]]
regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit()# Check the p-values of each predictor variable and remove the one# with the highest p-value (i.e., the least significant)
regressor_OLS.summary()# Repeat the above step until all the remaining predictor variables# have a p-value below the significance level (e.g., 0.05)
X_opt = X[:,[0,1,2,3,5,6,7,8]]
regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit()
regressor_OLS.summary()
X_opt = X[:,[0,1,3,5,6,7,8]]
regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit()
regressor_OLS.summary()
X_opt = X[:,[0,1,3,5,7,8]]
regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit()
regressor_OLS.summary()
X_opt = X[:,[0,1,3,5,7]]
regressor_OLS = sm.OLS(endog = y, exog = X_opt).fit()
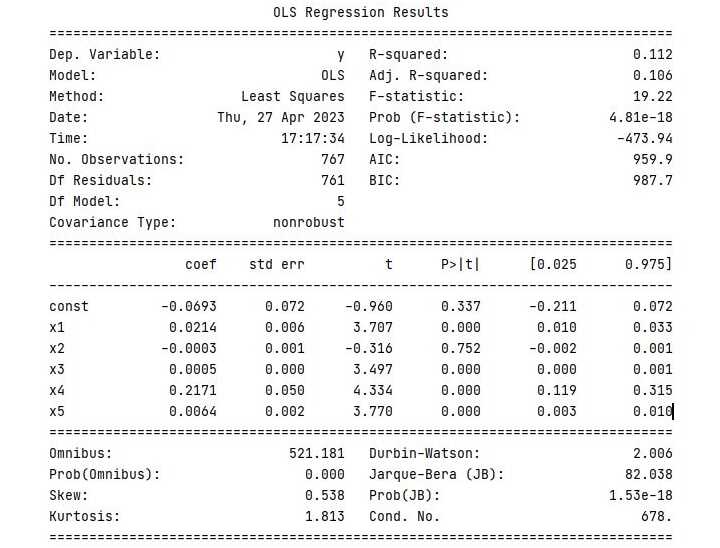
regressor_OLS.summary()Output
When you execute this program, it will produce the following output −
Leave a Reply