The Insert on Duplicate Key Update statement is the extension of the INSERT statement in MySQL. When we specify the ON DUPLICATE KEY UPDATE clause in a SQL statement and a row would cause duplicate error value in a UNIQUE or PRIMARY KEY index column, then updation of the existing row occurs.
In other words, when we insert new values into the table, and it causes duplicate row in a UNIQUE OR PRIMARY KEY column, we will get an error message. However, if we use ON DUPLICATE KEY UPDATE clause in a SQL statement, it will update the old row with the new row values, whether it has a unique or primary key column.
For example, if column col1 is defined as UNIQUE and contains the value 10 into the table tab1, we will get a similar effect after executing the below two statements:
mysql> INSERT INTO tab1 (col1, col2, col3) VALUES (10,20,30) ON DUPLICATE KEY UPDATE col3=col3+1;
mysql> UPDATE tab1 SET col3=col3+1 WHERE col1=1;It makes sure that if the inserted row matched with more than one unique index into the table, then the ON DUPLICATE KEY statement only updates the first matched unique index. Therefore, it is not recommended to use this statement on tables that contain more than one unique index.
If the table contains AUTO_INCREMENT primary key column and the ON DUPLICATE KEY statement tries to insert or update a row, the Last_Insert_ID() function returns its AUTO_INCREMENT value.
The following are the syntax of Insert on Duplicate Key Update statement in MySQL:
INSERT INTO table (column_names)
VALUES (data)
ON DUPLICATE KEY UPDATE
column1 = expression, column2 = expression…;In this syntax, we can see that the INSERT statement only adds the ON DUPLICATE KEY UPDATE clause with a column-value pair assignment whenever it finds duplicate rows. The working of ON DUPLICATE KEY UPDATE clause first tries to insert the new values into the row, and if an error occurs, it will update the existing row with the new row values.
The VALUES() function only used in this clause, and it does not have any meaning in any other context. It returns the column values from the INSERT portion and particularly useful for multi-rows inserts.
MySQL gives the number of affected-rows with ON DUPLICATE KEY UPDATE statement based on the given action:
- If we insert the new row into a table, it returns one affected-rows.
- If we update the existing row into a table, it returns two affected-rows.
- If we update the existing row using its current values into the table, it returns the number of affected-rows 0.
MySQL INSERT ON DUPLICATE KEY Example
Let us understand the working of the INSERT ON DUPLICATE KEY UPDATE clause in MySQL with the help of an example.
First, create a table named “Student” using the below statement:
CREATE TABLE Student (
Stud_ID int AUTO_INCREMENT PRIMARY KEY,
Name varchar(45) DEFAULT NULL,
Email varchar(45) DEFAULT NULL,
City varchar(25) DEFAULT NULL
);Next, insert the data into the table. Execute the following statement:
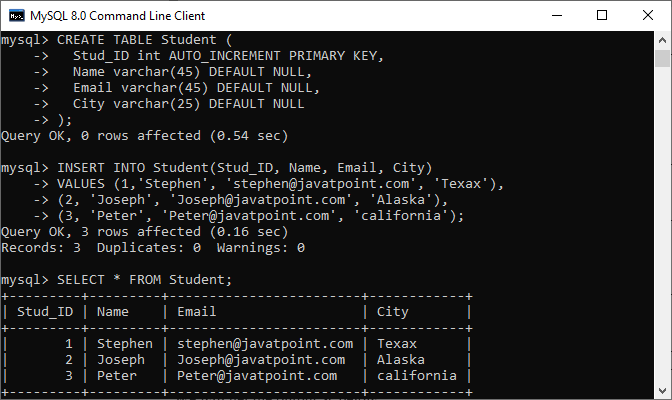
INSERT INTO Student(Stud_ID, Name, Email, City)
VALUES (1,'Stephen', '[email protected]', 'Texax'),
(2, 'Joseph', '[email protected]', 'Alaska'),
(3, 'Peter', '[email protected]', 'california');Execute the SELECT statement to verify the insert operation:
SELECT * FROM Student; We will get the output as below where we have three rows into the table:
Again, add one more row into the table using the below query:
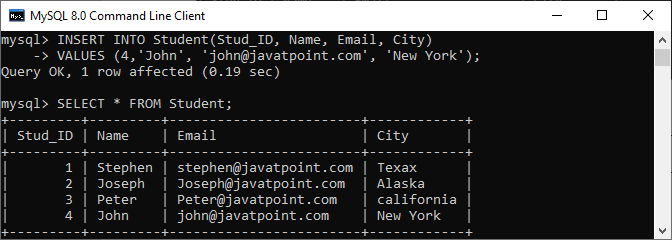
INSERT INTO Student(Stud_ID, Name, Email, City)
VALUES (4,'John', '[email protected]', 'New York');The above statement will add row successfully because it does not have any duplicate values.
Finally, we are going to add a row with a duplicate value in the Stud_ID column:
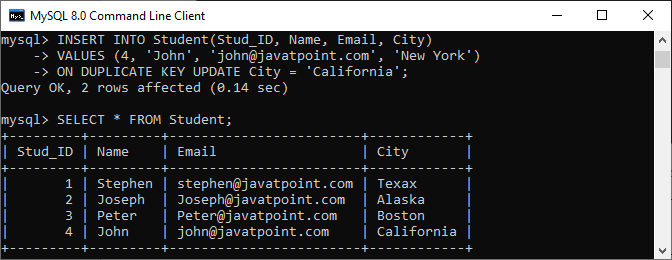
INSERT INTO Student(Stud_ID, Name, Email, City)
VALUES (4, 'John', '[email protected]', 'New York')
ON DUPLICATE KEY UPDATE City = 'California';MySQL gives the following message after successful execution of the above query:
Query OK, 2 rows affected.
In the below out, we can see that the row id=4 already exists. So the query only updates the City New York with California.
Leave a Reply