In this section, we are going to understand the working of GROUP BY clause in PostgreSQL. We also see examples of how GROUP BY clause working with SUM() function, COUNT(), JOIN clause, multiple columns, and the without an aggregate function.
The PostgreSQL GROUP BY condition is used with SELECT command, and it can also be used to reduce the redundancy in the result.
PostgreSQL GROUP BY clause
Most importantly, this clause is used to split rows into groups where the GROUP BY condition collects the data across several records and sets the result by one or more columns.
And every group can apply an aggregate function like COUNT() function is used to get the number of items in the groups, and the SUM() function is used to analyze the sum of items.
Syntax of PostgreSQL group by clause
The basic syntax of the GROUP BY clause is as follows:
SELECT column-list
FROM table_name
WHERE [conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnNThe following are the parameters used in the above syntax:
Columns-list: It is used to select the columns, which we need to group, and it could be column1, column2,…columnN.
We can also use the additional condition of the SELECT command with the GROUP BY clause.
In PostgreSQL, the working of GROUP BY clause is as following:
Examples of PostgreSQL GROUP BY clause
For our better understanding, we will take an Employee table, which we created in the earlier section of the PostgreSQL tutorial.

- Example of GROUP BY clause without using an aggregate function
Here, we will be using the GROUP BY clause without applying an aggregate function. So, we use the below command, which gets the records from the employee table, and groups the result through emp_id.
SELECT emp_id
FROM employee
GROUP BY emp_id;Output
After implementing the above command, we will get the below result:
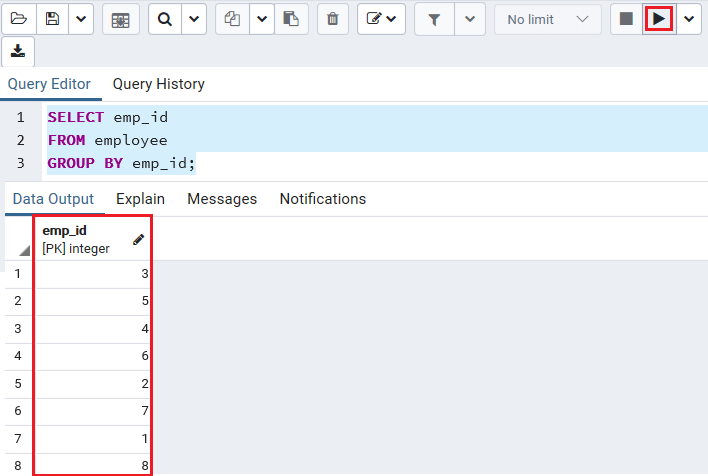
In the above example, the GROUP BY clause works similarly to the DISTINCT condition, which helps us to delete the matching rows from the result set.
- Example of SUM() function using PostgreSQL GROUP BY Clasue
Here, we are using the aggregate function with the GROUP BY condition.
For example, if we want to get the sum of salary whose first_name is John in the employee table. So, we use the where clause with GROUP BY clause to get the salary of John.
The below command is used to fetch the sum of John’s salary with the help of the GROUP BY condition:
SELECT first_name, SUM(SALARY)
FROM employee
where first_name = 'John'
GROUP BY first_name ;Output
After implementing the above command, we will get the below result:
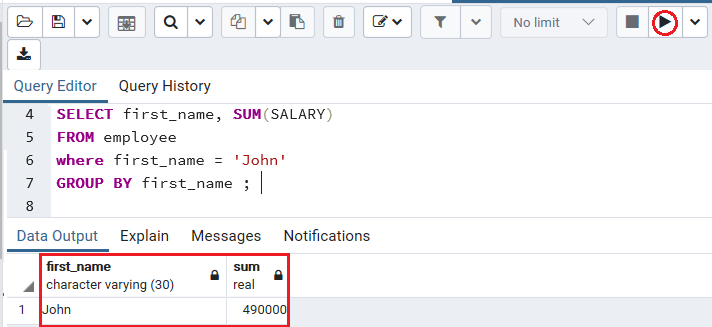
Note: In the employee table, we have the redundancy of first_name as john. After using this command, both the john’s salaries are merged because we use the where clause, and display the sum of the john salary.
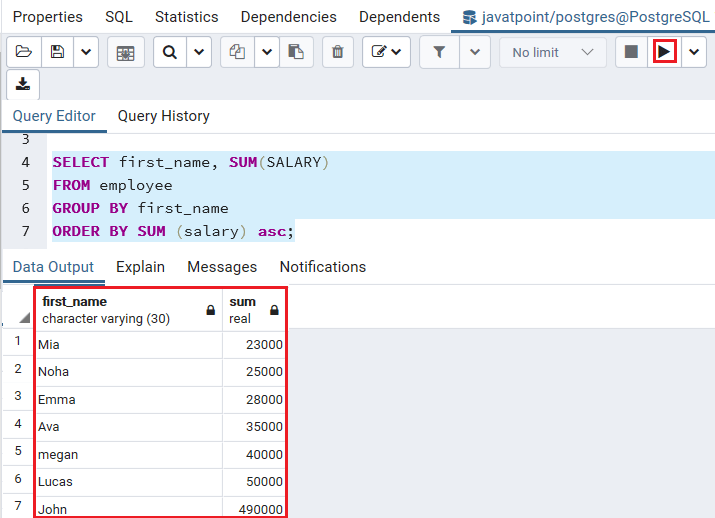
In the below command, we use the ORDER BY condition to display all employee’s salary in the ascending order with GROUP BY clause:
SELECT first_name, SUM(SALARY)
FROM employee
GROUP BY first_name
ORDER BY SUM (salary) asc;Output
After executing the above command, we will get the below output:
- Example of JOIN condition using PostgreSQL GROUP BY clause
In the below example, we use the GROUP BY clause with the INNER JOIN clause to get the sum of each employee’s salary.
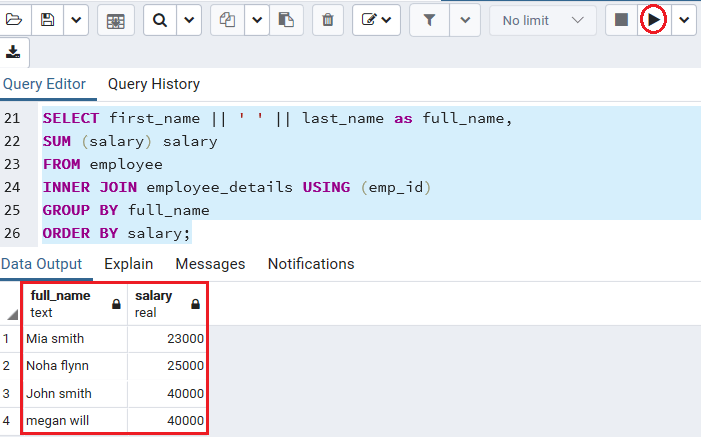
In the following command, we Join the employee table with the employee_details table and Concat (combine) the employee by their names.
SELECT first_name || ' ' || last_name as full_name,
SUM (salary) salary
FROM employee
INNER JOIN employee_details USING (emp_id)
GROUP BY full_name
ORDER BY salary;Output
After executing the above command, we will get the below result:
- Example of Count() function using PostgreSQL GROUP BY clause
In the below example, we use the COUNT() function to get the number of emp_id. So, we select the first_name and get the count of emp_id from the employee Table.
SELECT first_name,
COUNT (emp_id)
FROM employee
GROUP BY first_name;Output
After executing the above command, we will get the below result, where we can see that in thefirst_name column, we get the count as 2 for John.
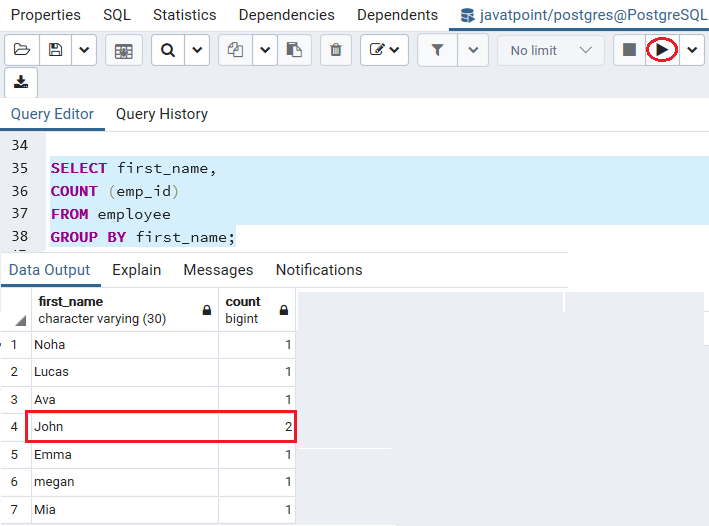
For each group, it returns the number of rows by using the COUNT() function. And the GROUP BY clause divides the rows in the employee into groups and groups them by value in the emp_id column.
- Example of multiple columns using PostgreSQL GROUP BY clause
In this, we will take one or more columns and get the records with the help of GROUP BY clause.
In the below example, the multiple columns we are taking are emp_id and first_name using the GROUP BY clause, which separates the rows in the employee table through their values, and for each group of emp_id and first_name.And the SUM() function is used to evaluate the total salary of each employee.SELECT emp_id, first_name, SUM(salary) FROM employee GROUP BY first_name, emp_id ORDER BY emp_id; OutputAfter executing the above command, we will get the below result:
Leave a Reply